



Active Topics
-
Firefox with Leste (10)
to Maemo 7 / Leste by teroyk - 2 days, 21 hrs ago - more...
 |

|
2011-02-08
, 15:37
|
|
Posts: 3,524 |
Thanked: 2,958 times |
Joined on Oct 2007
@ Delta Quadrant
|
#112
|
Originally Posted by attila77

Good post.
Two (well, three) problems.
1. The predictions are based on how native compilers worked ten years ago and assume that they won't *qualitatively* be different in the future. From .NET and LLVM implementation we already know this is not true, so your baseline what you need to get better than IS moving upwards.
2. Occam's razor works against you. You know that the Java-ish VM approach has both advantages and disadvantages. There has been a tanker-loads of money sunk into optimizing it by Sun, IBM and Google. Where this turns into occam's razor is that 5-10 years later, it's still objectively slower, so either the perceived benefits are not as huge or as easily implementable as thought 10 years ago, or everybody at Sun/IBM/Google is an idiot. Your pick.
3. This 'compiler/VM/interpreter technology advances will make all current languages obsolete' is a repeating thing. I remember when lisp/prolog were the next big thing. Just imagine, you don't need to define procedures how tasks are done, so in theory a good interpreter can make a better native code path than a human programmer ever could ! The key here is - in theory. Academic papers will be happy to point out corner cases in which alternative approaches beat out the incumbent one, but we're not in the business of academic papers - software development is engineering, and engineers have the tools of today to build the applications of today.
Disclaimer (again): I was a Java guy, but nowadays I do C++ (w Qt) by day and Python by night.
To point 1 and 2:
But JavaVM != DalvikVM. One is stack based, and the other register based, which has huge implications in its implementation and thus optimization. Dalvik's .dex files are much closer to the code segment in an ELF, than are java's class file.
http://www.usenix.org/events/vee05/f...p153-yunhe.pdf
I won't make allusions to which is superior, but they are different.
To your point 3. Supporting said obsolete language is as difficult as compiling a single interpreter, rather than the complete library of apps.
|
|
2011-02-08
, 15:45
|
|
Posts: 3,524 |
Thanked: 2,958 times |
Joined on Oct 2007
@ Delta Quadrant
|
#113
|
Here's a good post that I found to add fuel to the VM vs. Native fire:
http://www.javarants.com/2010/05/26/...to-the-iphone/
Unless your application has distinctly non-repetitive usage patterns, the JVM (or CLR, for that matter) will be on-par with C for a good many tasks. I wrote a video decoder in Java for a proprietary codec last year, and surprised the developer of the codec by outperforming his reference C implementation and being easily as fast (maybe a little faster) than his drop-to-MMX optimised version. Why? Because a JVM with a JIT can analyse how your code is running, not just how you or your compiler envisioned it running when the pre-optimised blob was written to disk. The JIT can also decide to use architecture-specific acceleration features (MMX, SSE) without you ever even knowing assembler; if you want to compete with that in C you'll need to cut-off all users below a certain CPU capability threshold and have a *very* good compiler. Frequently called methods that are not overridden in subclasses generally have monomorphic rather than polymorphic dispatch, avoiding a vtable lookup that a virtual method in C++ hard-codes at compilation. Small methods are often inlined into their callers when the running system demonstrates that it is required.
As for developer time: he spent a non-trivial amount of time writing and tweaking the assembler for the block transforms used by the codec. I just translated the vanilla C versions.
The downside? Memory, of course. While my decoder was as fast as the optimised C version, it consumed far more memory, even after a several passes through the code minimising the number of allocations (all that did was give me a very shallow memory growth curve and fewer garbage collects). Also, not all JITs are equal. Just because Dalvik now has a JIT doesn't necessarily put it on a par with modern HotSpot implementations.
There's also the lack of control. You can't shave cycles off of a tight loop by hand-crafting some assembler that takes advantage of some high-level knowledge that you, the programmer, have.
As to your last point, on battery life: the JIT will help here. Code that tries to run as fast as possible will accomplish what it's trying to do sooner; code that's task driven will accomplish those tasks with less load on the CPU. Both mean less of a drain on battery.
|
|
2011-02-08
, 15:45
|
|
Posts: 1,341 |
Thanked: 708 times |
Joined on Feb 2010
|
#114
|
Originally Posted by attila77
I mainly meant "deterministic response time" with that "time critical". There obviously are applications, device drivers and parts of the some applications (game 3D-engine) where we do not want VM or CG start to do code morphing, heap memory re-organizing or stuff like that but we want that part of the code run exactly as fast as in every other session.
Zimon, theory is one thing, reality is another (otherwise we'd be using lisp or prolog). 5-10 years after the papers you mention and a few million (billion?) $ thrown at it by Sun and Google, it's still 'not there yet'. Android giving in to the pressure and being polluted by native code tells the story pretty well. And people wanting to earn their bread and/or geek creds writing code are doing it today - we're talking about *today's* technologies, not the hypothetical performance in some unclear point in the future.
PS. As for time critical - in mobile space 'slow' translates into 'power-hungry' (because it goes against race-to-idle, etc).
And its true, theory is one thing and reality is another.
One can of course make all the running time profiling and heap memory optimizing and code morphing also writing in Assembly, or in C++/C; but that is not practical as one should also make one kind of VM and CG then and for example avoid direct pointers in the code.
Or, yes, one can trace some bytecode applications whole life time in a JIT-VM, and then output an Assembly source code of that, make one even tiny optimization by hand, and claim Assembly and fully compiled code is always faster than interpreted code. But on many applications once again the fully compiled program would in fact include some kind of VM and CG.
Or in theory, someone could fix the heap memory defragmentation problem with C++ programs, but once again he should write some kind of CG and use code morphing or avoid using direct pointers.
I do not know what modern VM optimization techniques are in use in Google's Dalvik VM, but I would guess they haven't yet reached the perfection in that, because there has been other issues to tackle first; like those changes they made to Java VM and also trying to go around Java license restrictions for mobile platforms.
In desktop Java some of the modern VM optimizations are already done, but not all. There is still space for improvements.
Another, good link explaining why interpreted code can be faster than fully compiled one, beside the two I already mentioned and which may be too technical and theoretic, is this:
http://scribblethink.org/Computer/javaCbenchmark.html
(It is kind of "old" also, but the facts haven't changed since then.)
Here is a relatively fresh benchmark test between Java and C++:
It's a tie!
http://blog.cfelde.com/2010/06/c-vs-java-performance/

Java VM is still getting better and faster. C++ optimizations are pretty much used already and not much else to do, unless CPU-manufacturers make Transmeta-type of features in CPUs, where MMU is made much more clever so for example heap memory de-fragmentation and object reorganization for L2-cache are done inside CPU.
| The Following User Says Thank You to zimon For This Useful Post: | ||
|
|
2011-02-08
, 15:56
|
|
Posts: 3,524 |
Thanked: 2,958 times |
Joined on Oct 2007
@ Delta Quadrant
|
#115
|
Originally Posted by zimon
A phenomenal read.
http://scribblethink.org/Computer/javaCbenchmark.html
(It is kind of "old" also, but the facts haven't changed since then.)
FTA:
Java is now nearly equal to (or faster than) C++ on low-level and numeric benchmarks. This should not be surprising: Java is a compiled language (albeit JIT compiled).
Nevertheless, the idea that "java is slow" is widely believed. Why this is so is perhaps the most interesting aspect of this article.
.......
Two of the most interesting observations regarding this issue are that:
- there is a similar "garbage collection is slow" myth that persists despite decades of evidence to the contrary, and
- that in web flame wars, people are happy to discuss their speed impressions for many pages without ever referring to actual data.
Together these suggest that it is possible that no amount of data will alter peoples' beliefs, and that in actuality these "speed beliefs" probably have little to do with java, garbage collection, or the otherwise stated subject. Our answer probably lies somewhere in sociology or psychology. Programmers, despite their professed appreciation of logical thought, are not immune to a kind of mythology.
Last edited by Capt'n Corrupt; 2011-02-08 at 15:59.
| The Following User Says Thank You to Capt'n Corrupt For This Useful Post: | ||
 |
|
2011-02-08
, 16:08
|
|
Posts: 2,427 |
Thanked: 2,986 times |
Joined on Dec 2007
|
#116
|
Until there's some clarification, I call FUD.
From this link off the same page I see this:
Either the graph is wrong, or the above is wrong; I'm guessing the former.
From this link off the same page I see this:
Code:
[keith@leak bench]$ time cpp/nestedloop 45; time cpp/nestedloop-386 45; time java -server -cp java nestedloop 45 -286168967 real 0m15.323s user 0m15.080s sys 0m0.020s -286168967 real 0m12.915s user 0m12.630s sys 0m0.050s -286168967 real 0m23.853s user 0m23.420s sys 0m0.040s [keith@leak bench]$ time java -cp java nestedloop 45 -286168967 real 0m32.779s user 0m32.570s sys 0m0.080s
__________________
N9: Go white or go home
N9: Go white or go home
|
|
2011-02-08
, 17:08
|
|
Posts: 3,524 |
Thanked: 2,958 times |
Joined on Oct 2007
@ Delta Quadrant
|
#117
|
Originally Posted by daperl
Sorry I don't understand this post -- but would like to. What are you referring to?
Until there's some clarification, I call FUD.
From this link off the same page I see this:
Either the graph is wrong, or the above is wrong; I'm guessing the former.Code:[keith@leak bench]$ time cpp/nestedloop 45; time cpp/nestedloop-386 45; time java -server -cp java nestedloop 45 -286168967 real 0m15.323s user 0m15.080s sys 0m0.020s -286168967 real 0m12.915s user 0m12.630s sys 0m0.050s -286168967 real 0m23.853s user 0m23.420s sys 0m0.040s [keith@leak bench]$ time java -cp java nestedloop 45 -286168967 real 0m32.779s user 0m32.570s sys 0m0.080s
|
|
2011-02-08
, 18:24
|
|
Posts: 2,427 |
Thanked: 2,986 times |
Joined on Dec 2007
|
#118
|
Originally Posted by Capt'n Corrupt
For the nestedloop test the graph shows C++ at about 12.5 seconds, and Java at about 1 second.
Sorry I don't understand this post -- but would like to. What are you referring to?
The same guy's benchmark data shows C++ at 12.63 seconds, and Java's best time at 23.42 seconds.
Something's off, and I'm guessing it's the graph's nestedloop Java number. It should look more like this:
Not like this:
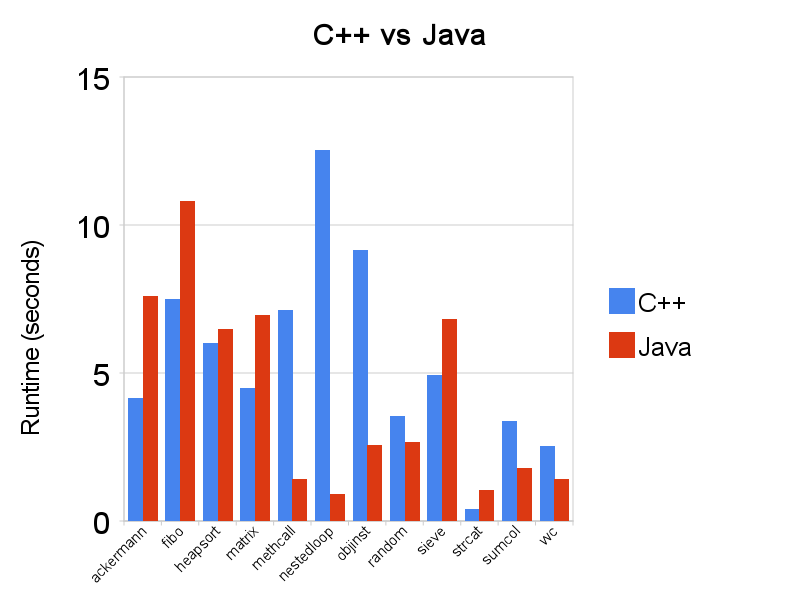
__________________
N9: Go white or go home
N9: Go white or go home
| The Following 2 Users Say Thank You to daperl For This Useful Post: | ||
|
|
2011-02-08
, 18:55
|
|
Posts: 3,319 |
Thanked: 5,610 times |
Joined on Aug 2008
@ Finland
|
#119
|
Java VM is still getting better and faster. C++ optimizations are pretty much used already and not much else to do
 Want an example ? Say hello to LLVMs or to the CLR.
Want an example ? Say hello to LLVMs or to the CLR.
Originally Posted by zimon
It's bull****, pardon my language. I have yet to see a benchmark that does not fall into the trap of the author being more proficient with one language than the other, and therefore skewing the results by his 'stronger' language getting a bias. Or you know, realizing that there are different C++ compilers in the world. 3 years ago, most of my Java apps beat my C++ apps speedwise, simply because I knew a lot better how Java works and what is expensive. Nowadays, my C++ runs circles around my Java. So there, there is only one language benchmark that is worth more than a dime - real life.
Another, good link explaining why interpreted code can be faster than fully compiled one, beside the two I already mentioned and which may be too technical and theoretic, is this:
http://scribblethink.org/Computer/javaCbenchmark.html
(It is kind of "old" also, but the facts haven't changed since then.)
Here is a relatively fresh benchmark test between Java and C++:
It's a tie!
Here is a small example how just a little more understanding of C++ can change the result of the very same tests you mention:
http://bruscy.republika.pl/pages/prz..._than_cpp.html
And I would say this is rubbish too, because there are omissions in the Java code, too, so the Java numbers could be made better, too. But then someone could that that's rubbish too because the tests weren't made with Intel's wicked-evil auto-parallellizing, CPU-architecture/extension aware C++ compiler. But that would be rubbish too, because someone would say that doesn't apply because that's just for Intel stuff. Do I need to go on ? You're beating a dead horse here. Apples. And. Oranges.
As one knowleadgeable dude very aptly put it:
There are only two kinds of programming languages: those people always ***** about and those nobody uses.
__________________
Blogging about mobile linux - The Penguin Moves!
Maintainer of PyQt (see introduction and docs), AppWatch, QuickBrownFox, etc
Blogging about mobile linux - The Penguin Moves!
Maintainer of PyQt (see introduction and docs), AppWatch, QuickBrownFox, etc
|
|
2011-02-08
, 19:19
|
|
Posts: 1,341 |
Thanked: 708 times |
Joined on Feb 2010
|
#120
|
Originally Posted by attila77
Even with LLVM, you will suffer if you have used pointers in C++/C program. You just have to throw many of the optimization techniques down the drain when there is a pointer inside some basic block.
And *I* get fingers pointed at me for dismissing future performance gains
The mentioned URI had good example why pointers are bad:
In C, consider the code
x = y + 2 * (...)
*p = ...
arr[j] = ...
z = x + ...
Because p could be pointing at x, a C compiler cannot keep x in a register and instead has to write it to cache and read it back -- unless it can figure out where p is pointing at compile time. And because arrays act like pointers in C/C++, the same is true for assignment to array elements: arr[j] could also modify x.
For Python, LLVM could be just what is needed to make it faster, but yet there is a problem with Python's dynamic types. As it is a problem for Python compiler, it is also a problem for intermediate code (IF) optimizer. You have to check here and there whether some variable is referring to different type later. Sometimes you just cannot know until running time.
When they were designing Java, they knew both pointers and dynamic types *are bad for you*.
But I still like the Python simplier and readable way better. Maybe just for speed optimization there could be a standard how dynamic types could optionally be bound to static types (separate file).
Last edited by zimon; 2011-02-08 at 19:23.
| The Following User Says Thank You to zimon For This Useful Post: | ||
 |
| Tags |
| bada rox, dalvik, future, java haters, meego, meego?fail, nokia, sandbox sucks |
«
Previous Thread
|
Next Thread
»
|
All times are GMT. The time now is 10:12.
I agree, native code and ASM inner loops are very quick. And I agree, many developers would often choose to develop based on what's available now.
But I'm not talking about future potential or speed comparisons. What I *am* implying is that there are many factors (eg. cultural) that stand in the way of development using VM. In the case of game development, game developers seem to love C++. And in my experience the most vocal of developers loath change.
Ok, onto performance:
But fast games *can* be coded in VM environments (see below). Hell even fast fully 3D games (w/ shaders) can be coded using Javascript (case and point: google's O3D). This was also before many of the fast optimizations to V8 (eg native compilation).
1) the latest Dalvik implementation compiles often used traces into native code with little memory penalty -- ~96-98% computed cycles are native including jumps at around 80KB memory penalty; put another way, very little time is actually spent in the interpreter and the memory consumption is negligible.
2) GC is largely controllable by the developer -- don't allocate new objects/temporary objects -- also, I think in Android the collector can be triggered by the developer (could be wrong). Bottom line, optimization is still a very active process regardless of the environment.
3) Core libraries are natively compiled and VM code (JIT or interpreted) simply calls them.
These are available today. I'm not saying that these optimizations are faster than native. What I *am* saying is that they are fast enough for most tasks -- even the intensive ones: games.
As the JIT trace compile optimizations become more mature, this will improve still, and I suspect the differences between compiled C/C++ and .dex to be negligible.
Here's someone that compared native with the VM on the HTC Hero:
http://marakana.com/forums/android/examples/96.html
Bottom line? In this test, non-recursive code is as fast as native compiled code. Recursive is another story altogether, but again, recursive code can be unrolled in the optimization step of development.